Detection总结一之rcnn系列
最近在做目标检测的相关项目, 对这一领域近几年的paper都梳理了一下. 总结归纳一下目标检测近几年的发展, 一共分为三篇来写, 分别是
-
1、基于Region Proposal的检测方法, 大概的脉络是RCNN — SPPNet — Fast-RCNN — Faster-RCNN.
-
2、直接做回归的检测方法, 大概的脉络是YOLO — SSD — YOLO 9000.
-
3、介绍一下目前state-of-art的一些检测工作, 它们代表着目前目标检测领域的基本潮流. 对现有的检测方法优缺点做一个总结
本文先梳理一下基于Region Proposal的检测方法. 在梳理中不会涉及太多细节, 只会谈一下大概的思路和每篇论文的关键点. 关于细节处可以去查看对应的paper.
RCNN系列基本步骤
- 1、在图像上提取Region Proposal, 可能存在物体的区域.
- 2、为Region Proposal形成特征.
- 3、利用分类器判断该特征, 决定该区域是否为某个物体类别.
- 4、利用回归器对Region Proposal的位置进行修正.
- 5、非极大值抑制等后处理.
RCNN — features matter, 将CNN引入目标检测
RCNN论文开篇第一句便说明了论文的关键工作 — 特征, 而特征提取正是CNN网络所擅长的地方.
回顾一下在RCNN之前目标检测的一个基本流程:
- A、在图像上进行不同尺度滑动窗口
- B、为窗口提取特征(SIFT/HOG等)
- C、特定分类器判断该窗口是否为某个物体类.
而RCNN的重大改进在于:
- 1、用CNN网络提取的特征替代步骤B中人为的设计特征(SIFT/HOG)
- 2、使用Selective Search等先行生成候选区域, 替代步骤A中的滑动窗口策略, 大大减少候选区域数量.
- 3、使用Regression进行窗口的进一步修正.
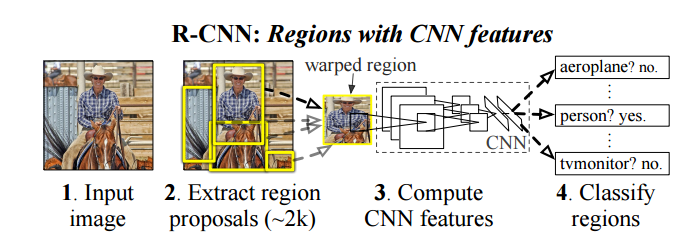
RCNN的基本步骤为
- 1、使用Selective Search生成候选区域, 并缩放到统一大小, 每一个候选区作为一张图像输入单位.
- 2、使用CNN网络提取特征. 此处CNN网络的训练为两个步骤:
a、ImageNet上的预训练.
b、将第一步生成的候选区标定正负后(IOU>0.5), 对网络层添加Softmax Layer进一步finetune. - 3、扔掉Softmax层, 将CNN作为特征提取器, 将候选区标定正负(IOU>0.3)后通过CNN网络, 最后的输出作为该候选区域的特征. 同时保存pool5层的特征用于后面回归.
- 4、利用3中形成的候选区域特征, 为每个类别训练一个SVM分类器.
- 5、将pool5的特征进行回归任务, 对候选框进行位置修正.
- 6、非极大值抑制等后处理.
RCNN中几个注意的点
- 1、Region Proposal会被resize/crop到同一大小, 因为网络中存在全连接层, 它们要求输入的大小不改变.
- 2、Softmax微调和SVM训练中使用了不同的IOU来划分正负.
- 3、做候选框修正时用的特征和训练SVM用的不一样, 使用的是pool5.
RCNN将CNN网络引入到了目标检测领域, 可以说是这一系列方法的开山之作. 但其存在几个明显局限.
RCNN的几个明显局限
- 1、训练分多阶段, 需要额外的硬盘存储.
- 2、每个Region Proposal作为一个独立的图像单元, 都会经过一遍CNN网络, 不共享计算, 耗时大.
- 3、Proposal会被缩放到统一大小, 而这会带来畸变, 物体不全等不利因素.
SPPNet — Spatial Pyramid Pooling 解决候选区resize问题
针对RCNN中存在的2、3缺点, SPPNet提出了Spatial Pyramid Pooling来进行改进. Spatial Pyramid Pooling能够接收不同大小的输入, 但产生相同大小的输出.
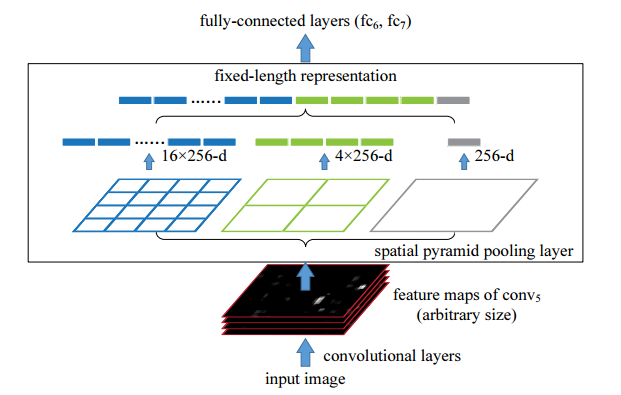
引入Spatial Pyramid Pooling后, SPPNet在以下步骤上与RCNN不同:
- 1、只进行一次全图的forward操作(到全连接层之前). 然后将Region Proposal映射到卷积层最后的feature map上对应的区域, 使得同一张图的Region Proposal共享了计算.
- 2、在Region Proposal对应在feature map上的区域, 通过Spatial Pyramid Pooling产生统一大小的feature输出.
- 3、由于消除了大小的影响, 所以在训练时使用了多scale的训练机制, 增加了尺度不变性, 防止过拟合.
同时此处需要注意的是, 经过Spatial Pyramid Pooling的feature先保存在了硬盘了, 所以在用Softmax进行finetune的时候只对后面的几个全连接层进行了fine-tune. 这个问题将在Fast RCNN里得到解决. 其之所以不对卷积层进行finetune的原因我们在后面说.
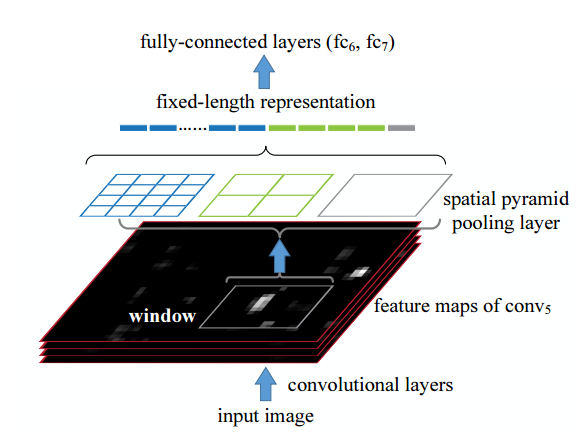
Spatial Pyramid Pooling基本含义
我们知道传统的pooling操作是以固定的滑动窗口大小对feature map进行滑动得到, 其输出与输入大小有关. 而Spatial Pyramid Pooling解决不同大小输入却同样大小输出的关键在于, 使用的是输入feature map的相对大小的滑窗来进行滑动. 相对大小的引入使得不同大小的feature map有与之对应的不同大小的滑动窗口, 从而便得到了统一大小的输出.
同时为了提取多尺度信息, 进行几个不同scale的相对大小pooling操作, 将它们拼接起来, 便形成了Spatial Pyramid Pooling的输出结果(如上图所示).
Spatial Pyramid Pooling的优点
- 1、不同的输入大小能产生相同的输出, 这解决了RCNN中需要先对候选区进行的resize操作.
- 2、使用几个不同scale的pooling操作, 作为对BOW(Bag Of Words)的一个近似, 提取了不同尺度的特征进行拼接, 使用了多层信息, 对物体形变等有一定作用. 其实当作用在整张feature map时, 其还能带来全局信息的整合, 避免误判 — 在CVPR 2017的一个做语义分割的工作PSPNet中就是用了这个特性. 不过这里并没有使用该特性综合全局信息(关于这一点我们在后面再讨论).
- 3、由于其消除了大小影响, 所以可以进行Variable-Image size的训练, 在训练的时候变换图像的大小, 可以有效防止过拟合(这种训练方式在以后很多工作中都很常见).
SPPNet的引入主要想解决的是RCNN中Region Proposal的缩放问题(因为两个网络都存在全连接层, 需要输入固定大小).
SPPNet还存在的局限
- 1、训练和RCNN一样还是分多阶段进行, 还是需要额外的硬盘存储.
- 2、Finetune的时候仅对全连接层做了微调.
Fast R-CNN — ROI pooling & Multi-task loss解决多阶段训练和硬盘缓存问题
Fast R-CNN顾名思义就是比较快的RCNN, 那么它快在哪里, 相比于SPPNet又进一步解决了哪些问题呢?
前面我们说到SPPNet中还是使用多阶段的训练方式, 并且还需要额外的存储. Fast R-CNN通过引入ROI pooling以及Multi-task loss将训练都放在网络中来进行. 至此除了Region Proposal的提取外其余的都是利用卷积神经网络来解决了.
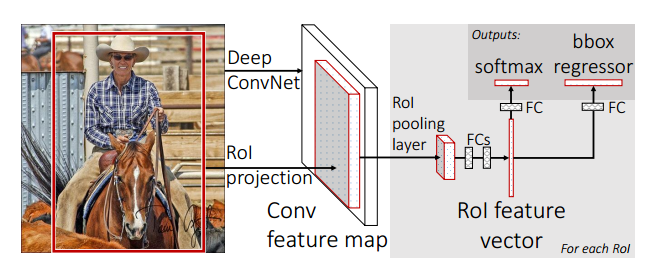
Fast R-CNN基本步骤
- 1、使用区域提取方法生成Region proposal.
- 2、将RGB图通过CNN卷积神经网络, 生成feature map. 注意此处的CNN网络一样经过ImageNet上的预训练.
- 3、将Region proposal映射到feature map上, 并通过ROI pooling提取feature.
- 4、将feature 通过几个全连接层最后分为两部分, 一部分用于预测box的修正, 一部分用于判断是否为物体, 即Multi-task loss.
下面具体来说说其改进之处.
ROI pooling
ROI pooling借鉴了SPPNet中的spatial pyramid pooling, 其实质是只包含一个scale的spatial pyramid pooling, 所以得到的结果也是尺度无关的.
这个地方不同之处在于, 在训练过程中Fast R-CNN不会先将这些feature缓存起来, 而是直接在挑选后进行前向传播, 并在反向传播时传播回前面的卷积层, 这样前面的参数便也得到了更新. 这一点是其与SPPNet中很大的不同之处. 因为在SPPNet中, feature经过了缓存, 而后再随机挑选进行训练, 此时如果想要更新前面的卷积层便很困难了—因为需要把所有feature对应的image都前向传播一次, 这十分低效.
比如在Fast R-CNN中, 先随机挑选了N张图像, 进行前向传播, 然后再从每张图像中选择\(\frac{R}{N}\)个Region proposal进行计算和更新. 但是在SPPNet中, 如果要达到R个Region proposal同样的效果便需要前向传播R张图像(假设R个区域来自不同的图像). 显然Fast R-CNN要高效得多. 由于前面的卷积层得到了更新, 整体检测效果也得到了提升.
Multi-task loss
相比于之前先用softmax微调, 再用svm训练, 最后再用regression进行回归调整的方法. Fast R-CNN将这个过程整合到了一起, 避免了硬盘存储.
具体来说网络的最后输出分为了两个分支, 一个分支输出为C+1(含背景)用于判断是否某个类, 另一个分支为4C输出用于对box进行回归调整.
可以说这一设计十分巧妙, 以后的detection任务中基本都是基于这个loss思路的变型.
此处 \(u\)代表类别, 控制了只有当存在物体时regression的loss才会有贡献值, 而 \(v=(v_x, v_y, v_w, v_h)\)表示真实坐标值, 而\(t^u\)表示预测值. 注意此处的回归问题是没有约束的, 为了避免回归函数对于outlier过于敏感, 使用了分段的损失函数
即只有当值较小时使用欧拉距离, 否则使用\(L1\)距离.
到此为止检测工作中除了Region Proposal的产生外都是由卷积网络来完成的了, 而且没有中间的缓存步骤, 基本实现了端到端.
Fast R-CNN中还存在局限
- 1、Region Proposal的产生还是传统方法, 成为速度瓶颈.
- 2、使用的box坐标预测值是unbounded的.
Faster R-CNN—RPN网络提取proposal, 所有工作统一到CNN网络结构中来
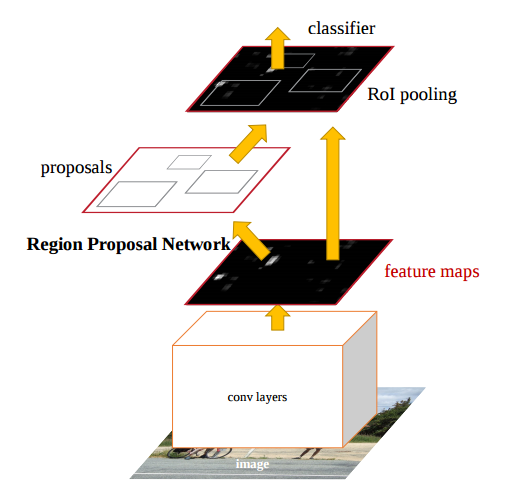
在Fast R-CNN后, 这一体系的相关方法便只剩Region Proposal的提取为速度和精度瓶颈了. Faster R-CNN提出了Region Proposal Networks(RPN)用于提取proposal, 通过与Fast R-CNN共享大部分卷积层, 实现了实时的Region Proposal提取, 同时由于这些proposal从数据中学得, 会受益于好的feature. Faster R-CNN可以看做是RPN与Fast R-CNN的一个结合.
Region Proposal Network(RPN)的基本概念
RPN接收一张图像, 输出一系列的Region Proposal和其对应的score. 注意此时的Region Proposal是不带类别属性的.
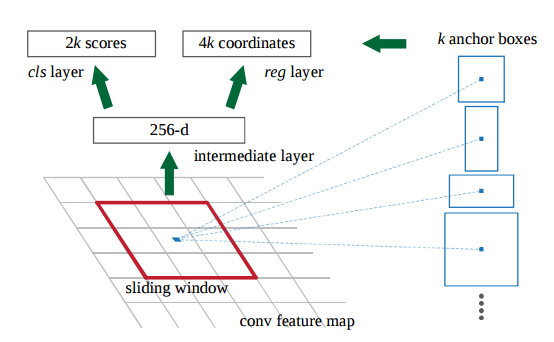
RPN可以看做一个全卷积的网络结构(FCN), 图像经过一系列的卷积层后, 输出一张feature map. 其基本步骤基本表达为
- 1、图像经过一个全卷积网络产生一张feature map.
- 2、在这张feature map上, 以\(n \times n\)(这里是3)大小的feature为单位, 将每个这样大小的区域连接映射到256维的全连接层.
- 3、将上面\(n \times n\)大小的feature区域中心投射回原rgb图上, 提取k个(这里采用3个scale, 3个ratio, 共9个)的候选框anchor. 这样第二步中的每个\(n \times n\)的feature便可作为一个独立单位, 对应于k=9个anchor.
- 4、将第二步中生成的feature进一步分开连接到两个全连接层. 一个为2k的score层, 用于判断这k个anchor为正还是为负(即是否为有效proposal), 另一个为4k的坐标层, 用于对这k个anchor的坐标进行修正.
注意到上面每个\(n \times n\)的feature都共享了后面的全连接层, 因此可以通过一个大小为\(n \times n\), 卷积核个数为256的卷积操作; 再分别加上两个\(1 \times 1\), 卷积核分别为2k和4k的卷积操作来实现这一过程. 可以看到整个RPN网络是全卷积形式的.
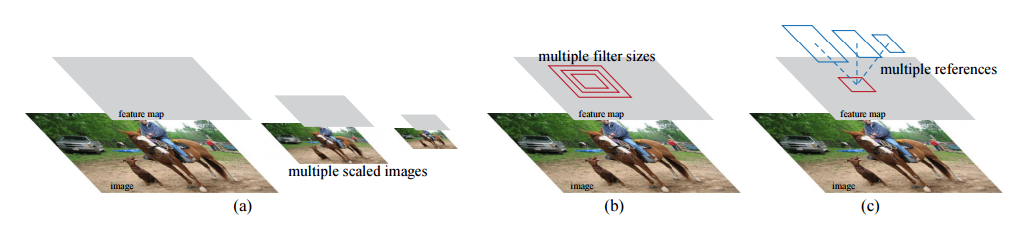
特别注意此处anchor的选择上, 每一个固定大小\(n \times n\)的feature区域都负责一系列不同尺度和大小的anchor, 作者将其称为a pyramid of anchors, 利用其解决图像金字塔/特征金字塔想解决的多尺度问题. 与之对应的则是预测结构的设计, 在Fast R-CNN中的基本步骤是从任意大小的ROI区域提取相同大小的feature, 然后以每个ROI区域的feature作为一个单位进行训练—regression weights是被所有feature共享的, 只训练一个regressor. 而在这里是以\(n \times n\)的feature作为一个单位, 而每个区域对应于k个可能ROI区域, 所以训练了k个regressor.
在损失函数的设计方面, RPN借鉴了Fast RCNN以及RCNN中的设计. RPN这种基于先验知识的box提取方法十分经典, 后面被yolo v2等方法借鉴.
在训练好RPN以后便可以直接用其提取Region Proposal, 然后结合Fast R-CNN来做进一步的detection工作了. 由于RPN和Fast R-CNN共享了前面的卷积层, 怎么进行训练便成为一个问题, 作者提出了4-step training. 具体来说为:
- 1、用ImageNet pretrain的model初始化网络, 训练RPN.
- 2、用ImageNet pretrain的model重新初始化一个网络, 同时用1中训练好的RPN网络产生Region Proposal来训练detection任务.
- 3、固定住2中网络的共享CNN层, 只训练RPN部分.
- 4、继续固定住3中网络的共享CNN层, 用3产生的region proposal只训练detection的子部分.
至此基于Region Proposal的detection方法就都统一到CNN网络中来进行了, 算是完成了深度学习搞定detection的大统一, 当然后面还有很多改进工作的进行. 结合做semantic segmentation研究热点, 我个人认为目前主要有两个可能的改进方向.
- 1、一是怎样结合更多的细节特征, 更好的解决尺度scale问题. 可以看到这一系列的Detection方法都是直接在最高层feature上进行的操作, 很多还只利用了一部分特征. 高层特征的一个缺陷就是小物体的特征得不到有效表达, 同时会丢失细节. 这使得比例较小的物体的检测较为困难.
- 2、二是怎样综合全局特征, 考虑更多全局语义信息. 全局语义信息的加入有利于结合语义, 避免误判等情况.
参考文献
[1]Girshick R, Donahue J, Darrell T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2014: 580-587.
[2]He K, Zhang X, Ren S, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[C]//European Conference on Computer Vision. Springer, Cham, 2014: 346-361.
[3]Girshick R. Fast r-cnn[C]//Proceedings of the IEEE international conference on computer vision. 2015: 1440-1448.
[4]Ren S, He K, Girshick R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[C]//Advances in neural information processing systems. 2015: 91-99.
[5]Zhao H, Shi J, Qi X, et al. Pyramid scene parsing network[J]. arXiv preprint arXiv:1612.01105, 2016.