CNN训练中的一些trick
从接触深度学习到现在已经过去很久了,从当初的一无所知到现在还算熟络,一路不知踩了多少坑,这里记录一下希望给遇到的人一个帮助也是给自己一个备忘吧。本文将从最开始网络结构的选择,网络的debug,网络的初始化调参,再到网络的训练过程总结给出一整个流程中我认为应该引起注意的事项。
一、网络结构的选择
如果想从头设计一个网络的话其实是挺tricky的一件事情,网络结构的设计往往需要结合具体的任务通过不断地trial and error,调节实现。一般来说不建议自己重头设计一个网络结构,许多现存的网络一般来说能够很好的fit当前的任务,比如ImageNet上有名的网络(AlexNet, VggNet, googleNet, ResNet),现在ResNet基本是人们的首选,它使用了一种skip连接的方式使得超深层网络的梯度消失问题得到解决,还有VggNet的结构相当优美,这些都是值得先去尝试的。当然如果确实有自己设计结构的需要,我们需要特别注意几点。
a、在Convolution层中使用较小的filter size
主要有两个原因,一是为了更好的特征表达,二是更少的参数。
卷积神经网络之所以能够这么成功,我认为就是它通过不断地叠加组合从图像中抽象出了一系列递进的高层语义的特征。打个比方,我们想通过CNN去识别一张图像中是否有一辆车,经过一系列的训练,可能第一层的filter被训练出去提取一些边缘结构,比如线条,点;第二层则在这些边缘结构上学习了提取稍微高层一点的特征,比如说圆;第三层则学习了更高级的特征比如说轮子。正是这样一个不断叠加升华的过程使得网络能够work。但是如果我们用了一个较大的filter size,那么可视域将会大大增加,这样一些局部的特征比如边缘等很可能就被错过,我们想要通过这样一个较大的filter来完成几个叠加的filter所完成的事情显然是不可能的。
并且使用较大的filter参数也会增加,比方说我们使用一个\(7 \times 7\)的filter,假设输入层的depth为1,那么我们将有\(7 \times 7 = 49\)个参数,而如果我们使用\(3 \times 3\)的filter,假设stride都为1的话,第二层对原始图的可视域为\(5 \times 5\),第三层为\(7 \times 7\), 即我们用3层\(3 \times 3\)的卷积层达到了一层\(7 \times 7\)一样的对原始图的可视域,但是我们的参数总数却只有\(3 \times 3 \times 3 = 27\)。
总结一下就是使用较小的filter size我们可以有更好的表达力以及更少的参数。除非明确图像中的特征是非常稀疏的,否则不建议使用较大的filter size。现在主流一般使用的都是\(2 \times 2\),\(3 \times 3\)大小。
b、pooling层也尽量使用较小filter size,同时尽量使用max pool
pooling的作用主要是进行模型的精简和参数的减少,以及引入特征的缩放不变性。因为在convolution层中我们尽量保持feature map的大小不坍塌,所以减少计算复杂度的任务只有交给pooling层了。pooling的破坏作用是破坏性的,以一个\(2 \times 2\)大小,stride为2的pooling为例,只有\(\%25\)的信息保存下来,当使用越大的filter size则越少的信息能保存下来。同时很多的实验和paper也证明max pooling的效果一般好于ave pooling,现在常用的是\(2 \times 2\)的max pooling。
c、减少fully connected layer
一般来说fully connected的使用不会超过3层,比如VGG16中使用了\(4096-4096-1000\)三个fully connected层。fully connected 层的作用其实越来越受到质疑,现在存在的趋势是取消掉fully connected层,比如ResNet中就使用了ave pooling来代替最后的fully connected layer实现标签数目的生成。
fully connected 层不太受到欢迎的主要原因是它对于系统性能并没有可论证的提升,但是计算量和参数量却是巨大的,很多时候整个网络层的计算都消耗在了全连接层。还是以VGG16层为例,整个网络的参数量大概有140M左右,但是对于第一个全连接层来说却有\(4096 \times 512 \times 7 \times 7 = 102760448\)个,将近100M!可以看到整个网络的参数几乎都集中在这一层了。
d、用ReLU及其变体
由于历史原因,sigmoid激活曾风行一时。但是现在几乎已经没人用了,sigmoid的函数图形如下所示
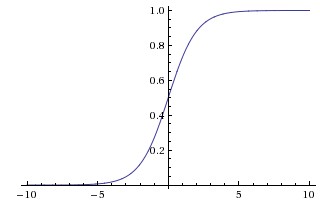
sigmoid主要有两个缺点,一是梯度消失问题,注意到函数的梯度在\(x\)的绝对值大于10左右的时候就会趋近于零,当反向传播的时候,残差流经这里会乘以该梯度值然后流向下层,于是下层所接受的梯度就几乎为零,消失了,此即梯度消失问题。二是注意到sigmoid函数并不是关于0对称的,输出都大于零,意味着sigmoid的下一层接受到的都是正输入,那么它们的weight更新的时候会都乘以正数,向着同一方向更新,虽然从整个网络的角度来看这不是太大的问题,但还是有一定的影响。
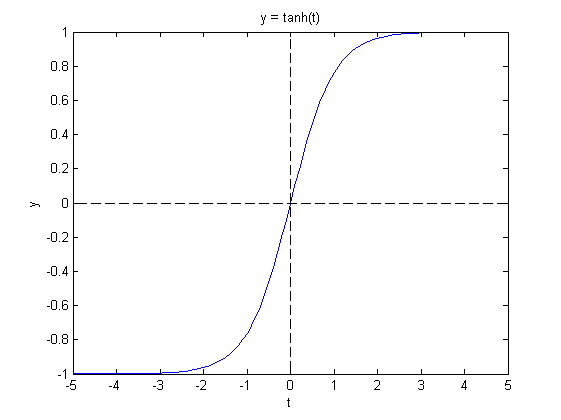
tanh激活函数有着差不多的特性,虽然也存在梯度消失问题,但是至少关于原点对称,所以如果一定要使用sigmoid形的函数话,建议使用tanh
ReLU函数\(x = max(0, x)\)即把小于零的部分截断,由于其分段线性的特性,不会存在梯度消失问题,梯度可以直接流过或这彻底截断。当然ReLU也存在着一些问题,比如神经元的失活,注意到当小于零后这些神经元将彻底不起作用了,针对这个问题也有人提出了一些leaky ReLU的思想,即给予其少量的激活而不全部置零
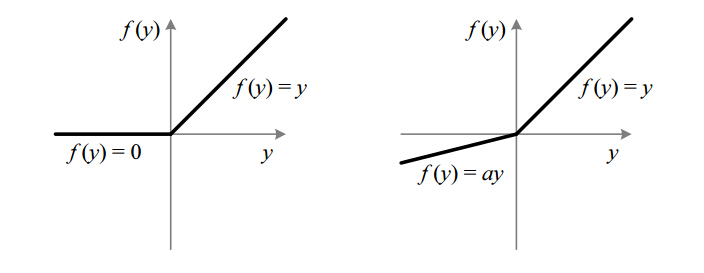
e、使用Dropout
Dropout可以被认为是一个最简单但又最实用的技巧,它起着一定的正则化的作用,使网络不会过拟合。要理解Dropout可以从两方面思考。一是Dropout可以被看做是一种Bagging思想的利用,我们每次都只训练网络的一部分,最终却把这些部分结合起来,唯一的区别在于这些网络的子部分是有很多参数共享的。二是可以从单个神经元的角度来思考,比如说某个神经元在一定的训练后已经学会了通过判断图像中有没有鼻子来判断是否有人脸的存在,此时我们对其采用了Dropout,神经元就不得不去学习另外的特征来判断人脸的存在与否,比如又去学习了眼睛这个特征,通过这样一个过程我们的网络便可以变得更加的鲁棒了。
除非网络实在很简单否则建议加上Dropout。
二、网络的Debug
这个主要针对自己实现网络层的情况,当我们自己向网络中添加了一个自定义层时,记得进行必要的检查,除了基本的逻辑外,最重要的就是梯度检查,即要让我们计算出的梯度大致等于数值梯度。检查可利用如下基本式子进行
三、网络的初始化以及训练
a、weights的初始化
一个良好的初始化是模型能够成功训练的保障。全部一致的weight会导致模型的参数更新朝着一个方向进行,而太小的参数则会导致梯度消失,太大则又会导致梯度爆炸。一个好的初始化应该是小而不同的,我们期望其呈现出均值为0的高斯分布,方差最好跟输入输出神经元个数相关,关于参数的初始化用很多的研究,目前最流行的是假设神经元的输出是n,那么初始化一般为np.random(n)/sqrt(n/2)。这里的2主要是解决ReLU层导致的输出减半问题。
如果网络很深的话建议使用BatchNorm,它强制每个Batch的数据变为了均值为0方差为1的数据分布,能够大大减少对初始化的依赖,同时在使用BatchNorm后我们可以采用更大的学习速率,实际上ResNet中为每一个Convolution层都使用了BatchNorm。
b、数据&网络check
在进行训练前一定要将数据进行过randomlize,否则网络可能很长一段时间内见到的都是同一类别的数据,当然得不到有效的训练。小技巧来粗略的确定网络以及数据没有问题,即:
保持学习速率为零,在数据上进行一段时间的训练,确保loss基本不会发生变化
这一步是很有必要的,因为正确的数据和网络能够保证你的loss基本恒定在一个平稳的水平,不会出现突然的暴涨或者下跌。在数据的check后下一步要做的是网络的表达力确定,即:
在一个很小的数据集上训练网络,确保网络能够很好的拟合数据,即loss能够降到很低
这是一个确保网络表达力的步骤,如果在很小的数据集上都不能很好的拟合的话,说明可能模型过于简单需要添加更多的层了。
c、学习速率 & Batch size
learning rate可以说是最重要的参数了,太大的学习速率可能会导致模型中能量过大,不能很好的降低到理想的值,甚至使得loss完全崩掉(当你看到loss出现NAN的时候,几乎就是学习速率过大了);而太小的学习速率又会使得学习进展十分缓慢。一般采用的策略是先采用一个较小的学习速率,然后逐步的增大,直到loss的下降是一个平缓而又不太缓慢的过程为止。这里套用一张常见的学习速率的图加以说明
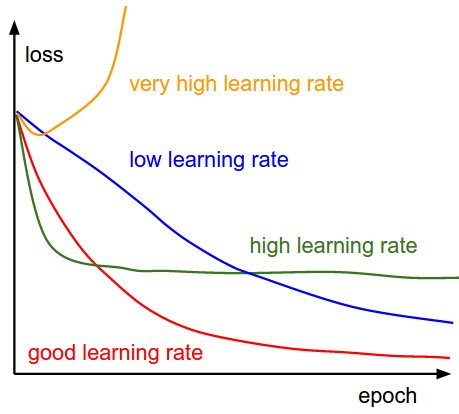
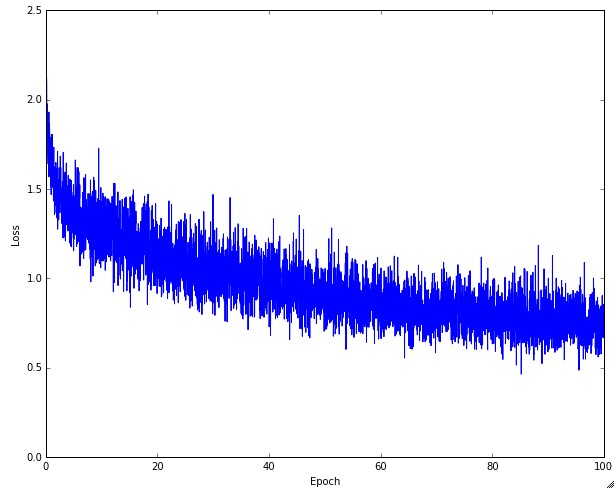
同时Batch size也是一个重要的因素,Batch size过小的话对于整体的数据没有很好的表征,那么整个loss图就会出现不断波动的情况,当看到如下这种loss图的时候,可以适当地增大Batch size
最后
不管是利用什么框架进行训练,请记得保存训练过程中的几个重要值一个是training loss,一个是test loss。一个训练良好而又没有过拟合的网络应该是它们的曲线图都呈现一个下降趋势,同时两者之间的距离不断靠近直到稳定,如果距离又出现了增大则说明有一定的过拟合了。